Get the latest on AI Search
New insights every week
Thank you for subscribing!
Oops! Something went wrong while submitting the form.


Most popular







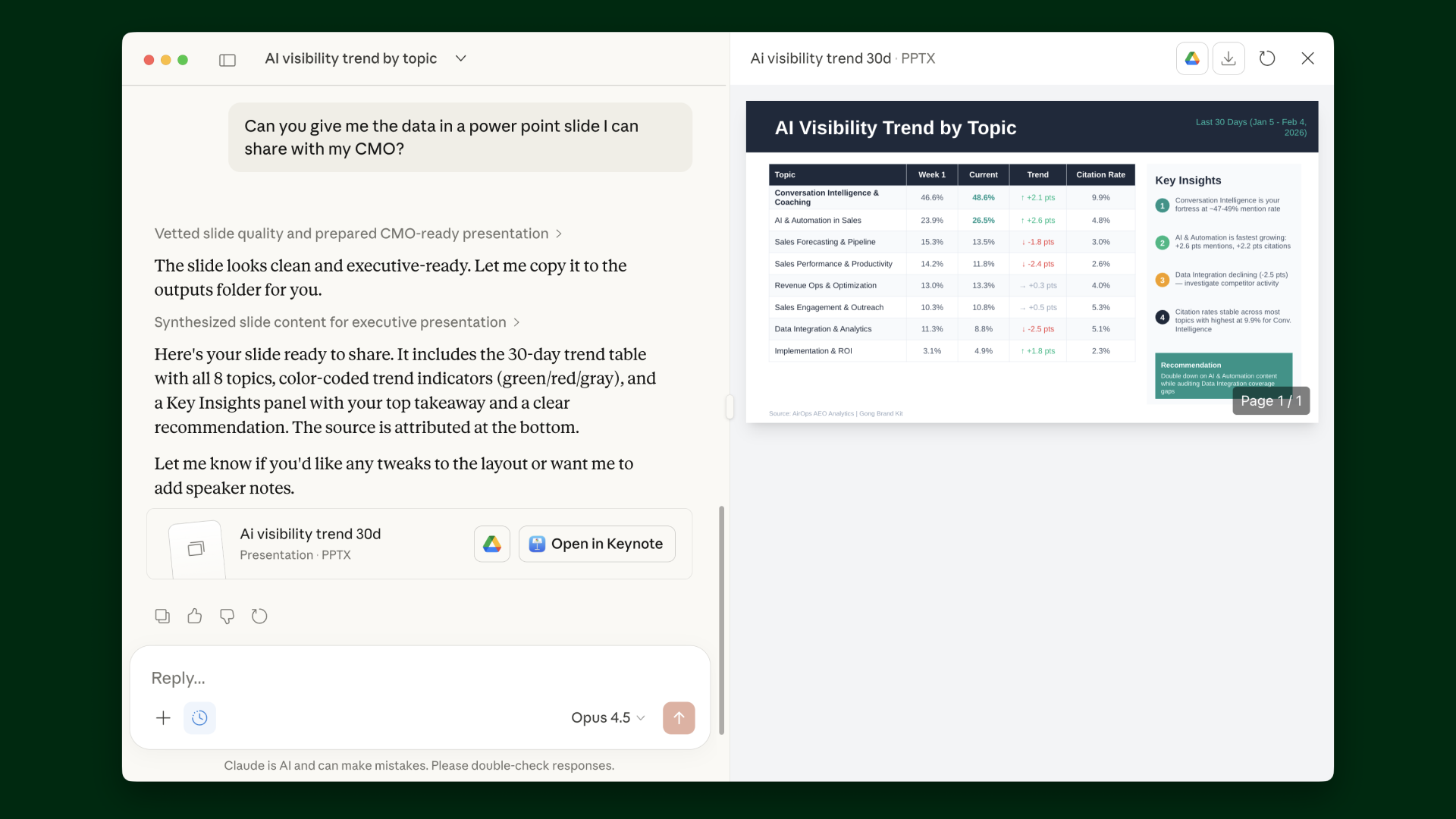
.avif)

.png)








.avif)

.avif)



.gif)

.avif)


g.avif)





.avif)

.avif)

.avif)

.avif)


.avif)

.avif)
.avif)

.avif)












.avif)

.avif)


Webinars, How Tos and more
.png)













.avif)
.avif)



-no-date.avif)
.avif)
Get the best and latest in AI Search delivered to your inbox each week.
Thank you for subscribing!
Oops! Something went wrong while submitting the form.
All Articles
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.






