The Playbook Builder Method: How Animalz Approaches AirOps Quill


- Act like a manager, not a micromanager. Brief with clear goals instead of scripting every step.
- Be generous with context and tools. Quill can pull what it needs, so you don't need to hand-feed it at each step.
- Use Artifacts as working documents. A QA checklist or decision journal running mid-Playbook quietly sharpens the final output.
- Stay engaged. Playbooks handle grunt work, but the judgment and quality bar are still yours.
For decades, computer vision was a hand-engineering problem. Researchers painstakingly built algorithms for spotting shapes in images, usually without much success. Then in 2012, three researchers from the University of Toronto entered the ImageNet competition with a deep neural network called AlexNet. Instead of relying on hand-engineered algorithms, their solution autonomously learned to recognize images by using lots of compute.
AlexNet won the competition by a margin that embarrassed everyone else, and within 18 months hand-engineered features had largely vanished from the field.
The computer vision story is the canonical example of what AI researcher Rich Sutton calls The Bitter Lesson: every time we try to encode our human understanding into AI systems, they lose to approaches that just throw more compute at the problem. As an extra twist, we also tend to forget the lesson and relearn it when we encounter the next AI challenge.
I’ve found the Bitter Lesson helpful to keep top of mind while switching from building Workflows in AirOps to using Quill, their agent captain, to create Playbooks. With Workflows, you need to spell out every step, and tweak minuscule parts of the process until everything works exactly how you want it.
Playbooks are different. You need to stay high level, define the outcomes you’re after, and let Quill turn your messy ideas into an organized Playbook for agent execution. In other words, let the computer do more of the work, as in the Bitter Lesson.
1. Act like a manager
Workflows need every step spelled out, because each step is an island, blind to what came before unless you pass it through.
Working with Quill is more like collaborating with a coworker. Quill already knows your brand, your competitors, your preferences, and the channel.
If you micromanage, you get exactly what you asked for, at best. But if you brief well, with clear goals and real context for why the work matters, it can figure out the what and the how, and even surprise you with something better. It’s the Bitter Lesson.
Professor Ethan Mollick uses a list of questions for briefing agents, which is essentially management 101, topic “delegation.”
They work well for creating with Quill, too:
What are we trying to accomplish, and why?
Where are the limits of the delegated authority?
What does “done” look like?
What specific outputs do I need?
What interim outputs do I need to follow your progress?
And what should you check before telling me you’re finished?
If your Playbook description answers these questions, you've done most of the work.
None of this means you should leave everything open. A good manager knows where to leave room for creativity and where to set hard requirements. It’s the same with Playbooks. Spell out what’s absolutely non-negotiable, leave space for Quill to surprise you everywhere else.
2. Err on the side of context
Providing the right context at the right time (”context engineering”) has always mattered if you want good results from an AI process. But how you do it with Playbooks is very different from Workflows.
In a Workflow, it's on you, and only you, to decide what context to include, where to put it, and how to use it. And you want to err towards being stingy, because too much information just overloads and confuses a step.
Playbooks change this in two places. While building, Quill can take a mountain of context, half-baked ideas and all, and help you sort out what actually belongs. This is especially true as context windows have expanded, allowing you to add more information without timing out the model.
.jpg)
Once the Playbook is running, it can reach for context on its own, so your job shifts from surgically feeding each step to making a rich and relevant information environment available so the agent can pull what it needs.
For example, in one of my first runs, I hadn't specified that the Playbook should add internal links to an article. But it figured out it had our whole site in an AirOps Knowledge Base, decided internal links were good practice, and added them without asking!
.jpg)
So be generous with the context you make available. Anything adjacent to the task can spark a solution you'd never have thought to wire in yourself.
3. Hand over the toolbox
The same thinking about context applies to tools: whereas Workflows required you to decide when and where to apply these tools, Quill works backward from your goals, and applies the right tools for the job.
Across a run, a tool might:
- bring data in (like pulling your AI SWearch performance numbers)
- do the actual work (like deep research with Parallel Web Systems)
- push results out (like a Slack ping when something's ready for review)
Scripting which tool fires at which step is exactly the hand-engineering the Bitter Lesson warns against. Stock a good toolkit instead, and the agent often finds a better path than the one you’d wire up.
Quill picks tools in two ways. You can instruct it directly ("use /Slack to post a message"), but it can also reach for tools on its own.
.jpg)
When Quill runs into a snag or spots an opportunity, it looks at the toolkit, weighs it against the context, and decides what might be a good move. That ingenuity makes it feel like a coworker.
In a Playbook, tools behave differently than in a Workflow:
- They're always available. The agent keeps the whole toolkit on hand for the entire run, not one tool bolted to a single step like a Workflow. So you can be generous, with one caveat: skip tools that overlap. Give it several options that do nearly the same thing and agents start reaching for the wrong one.
- They fail gracefully. When a tool fails to complete a job, the Playbook checks if another can. Say the default web scraper can't reach a source. The agent might then switch to a premium one that can.
- They can be built or customized. It's easy to BYO tools with Claude Code or Codex. For example, you could build an MCP server that calls your own product's internal API, so a Playbook can pull live data, like real usage numbers to ground a piece in your own facts.
From Copilot to Quill
Confession: when I started with AirOps in early 2025, the assistant back then, Copilot, wasn't my best friend. It often missed what I was asking for. That changed once it started running on Opus 4.x, and it has since grown into Quill, the version built for Playbooks.
Copilot waited for instructions. Quill watches what you're doing, drafts the brief, suggests which Playbooks to build, and runs them. You go from proposing the work to approving it. Plenty of my Playbooks started as a quick brief to Quill, which built a solid v1 on its own.
So if Copilot let you down a year ago, it's worth giving Quill another look.
4. Put Artifacts to work
Workflows race toward one deliverable. You can squeeze out more with some creative engineering, but it's clunky and error-prone.
Playbooks don't have that limit. A single run can produce several Artifacts at once: a brief, a draft, and a QA checklist, say, with little setup.
And an Artifact is more than an output. Where an output is whatever you get at the end of the run, an Artifact can be created early and kept up to date throughout. Build and maintain one as the Playbook runs, and it becomes a focus point that holds the agent's attention on whatever it tracks, quietly tightening the rest of the work.
A few examples of how Artifacts can add value (on top of the final deliverable):
- Claims ledger. A running CSV of every source the agent consults (type, link, whether it used it), which keeps it honest about sourcing instead of inventing references.
- QA checklist. The rules and quality bar the Playbook walks through every run, so output quality doesn't drift from one run to the next.
- Decision journal. A log of each decision, the reasoning, and where information was thin or conflicting, so you can see why the Playbook did what it did and fix where it struggled.
- Self-improvement doc. Drawing on the decision journal and the run as a whole, the Playbook suggests changes to itself, so it gets a little better every time you run it.
.jpg)
None of these is the output you're after, but each one changes how the agent works, and that carries straight into the output that counts. Which artifacts you have a Playbook keep is one of the quieter levers on the quality of its work.
5. Speak the same Playbook language
One of the quieter advantages of Playbooks is how legible they are. A Workflow's wired-up steps make sense mostly to the person who built them, so knowledge silos there.
A Playbook is written in goals and plain context, so you can build one with Quill on your own, and anyone on your team can still read it, push back, and help make it better.
That second part matters once a Playbook needs knowledge you don't hold yourself. You, the builder, make it work technically. The brand, the product, and the voice come from the experts, the SMEs who live in those things every day. That might be a PMM, an in-house legal reviewer, or someone else entirely; at Animalz it's usually the account lead who owns the brand, a content strategist, or our AEO specialist. Because the Playbook is legible, they can shape it directly instead of briefing you to do it for them.
But the moment more than one person is shaping a Playbook, you need a shared language for where you are and what's going wrong. We've found it comes down to two questions.
1. What phase are we in?
At Animalz, we've defined four phases a Playbook moves through as it matures: Design, Build, Calibrate, and Production. (These are the stages of building the Playbook itself, not steps you repeat for every piece it produces.) Naming the phase tells everyone what to expect. Here is our actual Playbook delivery cheat sheet at Animalz.
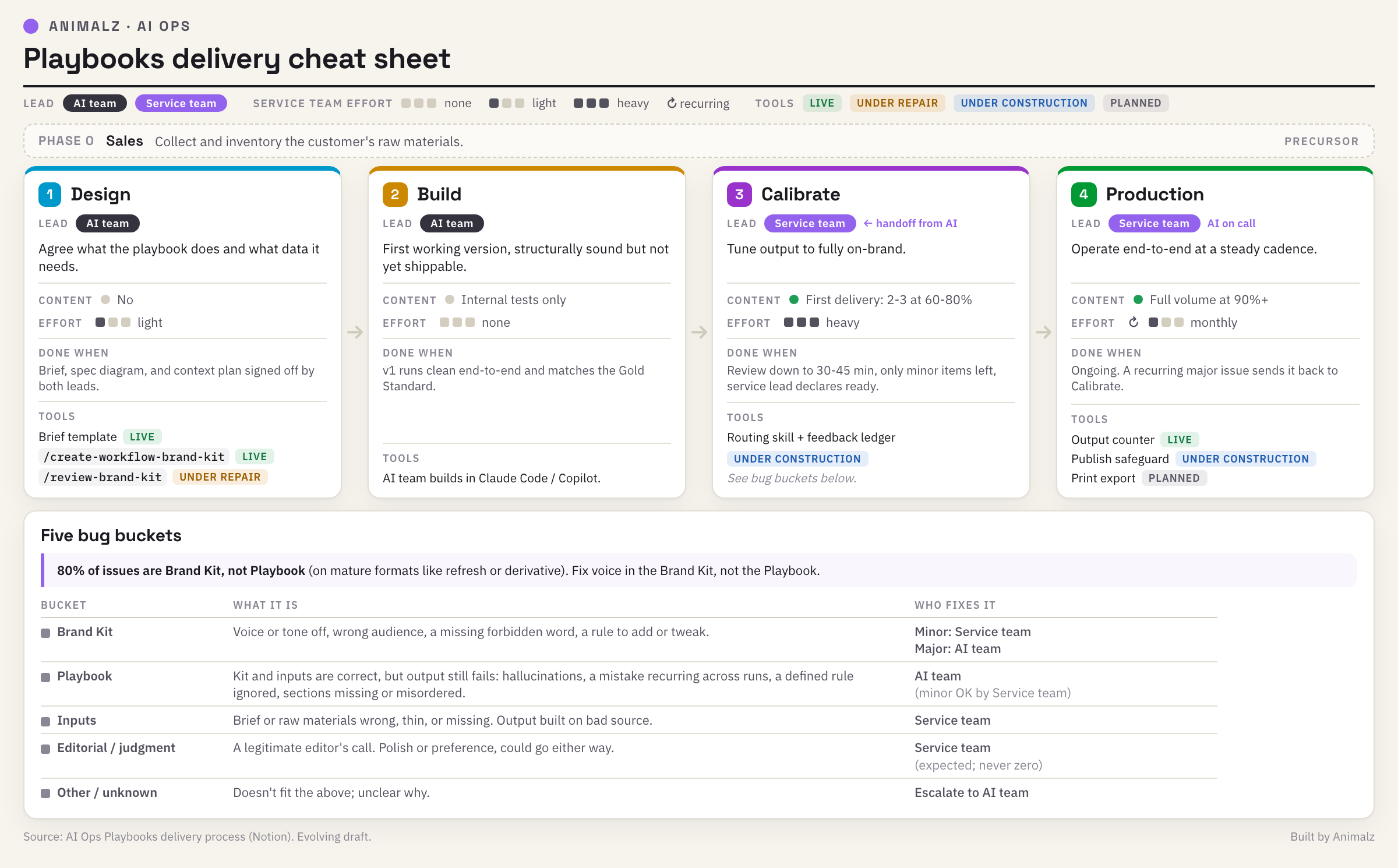
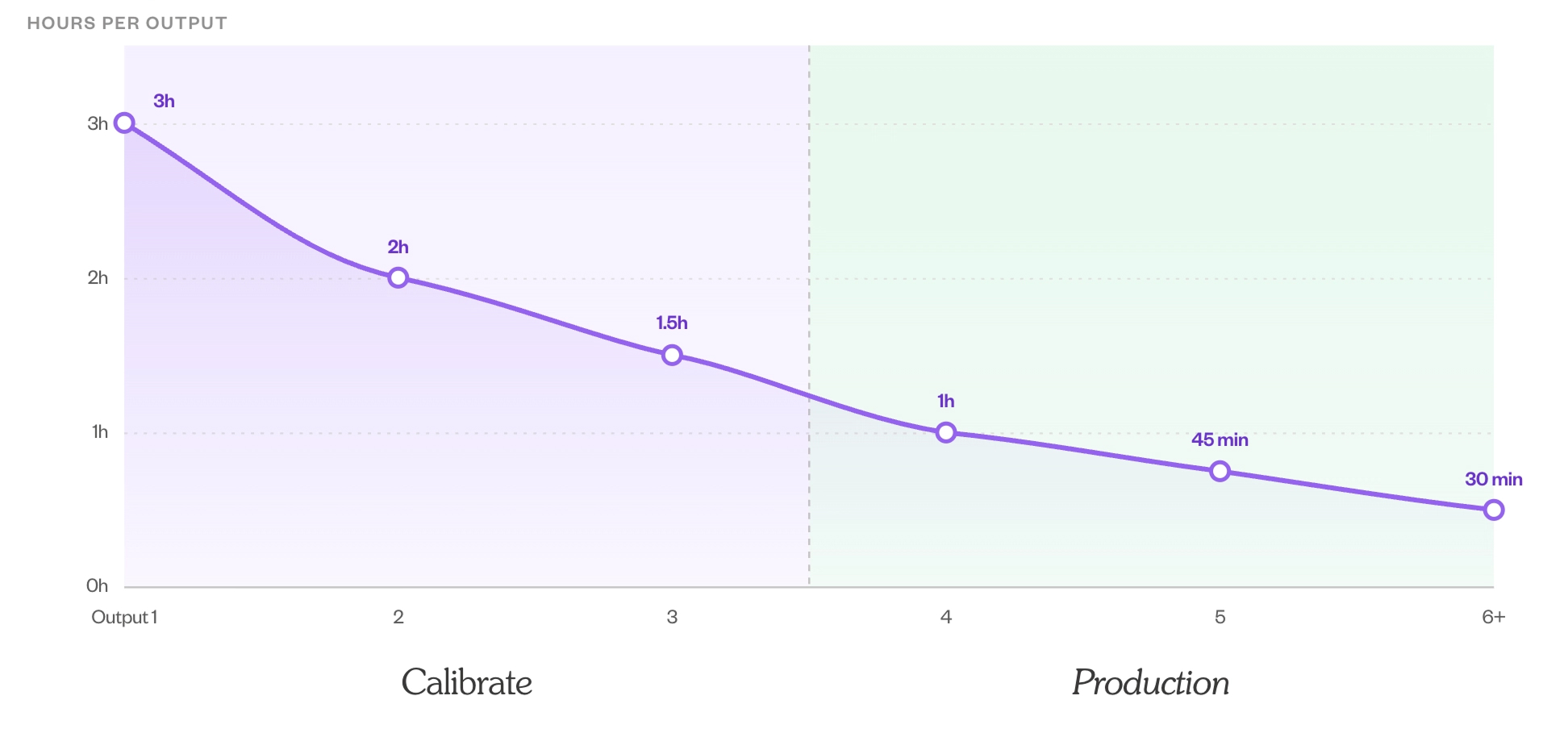
During Build, the builders are heads-down and the experts barely weigh in. The moment a Playbook hits Calibrate, that flips: the first outputs need real attention, often two or three hours of an expert's time to give the feedback that sharpens the next run (and the run after that needs less; see the chart).
Early on, before we named the phases, one of our experts opened a first draft expecting to barely touch it. They thought we were in Production. We were at the start of Calibrate, where rough first drafts are expected. Nothing had gone wrong. We'd just skipped the step of agreeing on where we were.
2. Where does the bug live?
When an output misses the mark, the instinct is to blame the Playbook. More often the problem is somewhere else, usually the Brand Kit, sometimes even in one of the inputs (e.g., an incorrect brief).
Before anyone rewrites the Playbook, we ask which bucket the issue belongs to, like the Brand Kit, the Playbook, or the inputs. That one question sends the fix to whoever owns that piece, instead of the builder and the expert pointing at each other.
Before we had this language, no one was sure where a problem lived or who should fix it. Now anyone can look at an output, name the phase, point to the bucket, and know who picks it up next.
Don't become a robot
By now you might be reaching a tempting conclusion: that the Bitter Lesson leaves less and less for you to do, that the agents and the compute have it handled, and your real job is just to press go.
That gets it backwards.
The Bitter Lesson clears the grunt work off your plate: the wiring and the mundane execution that Playbooks now handle well. What’s left is the part that was always hard: setting the right goals, asking sharper questions, giving feedback that actually fixes the run, judging whether the output is any good.
You’re still the most creative person in the room, the one who knows the brand best, the one on the hook for quality, the final defender against slop. That work matters more now, not less, and you finally have the room to do it.
But that same power is a trap.
Playbooks are strong for the reason AlexNet was strong: they lean on compute and agents instead of hand-built steps. They’re good enough now that you can go hands-off and still get a passable result, which is exactly what makes the pull to disengage so strong.
Rubber-stamp a brief here, let Quill build the whole thing there, stop reading closely, and before long you’re asleep at the wheel, anchored to whatever the agent suggested, sliding down the AI Dependency Spiral.
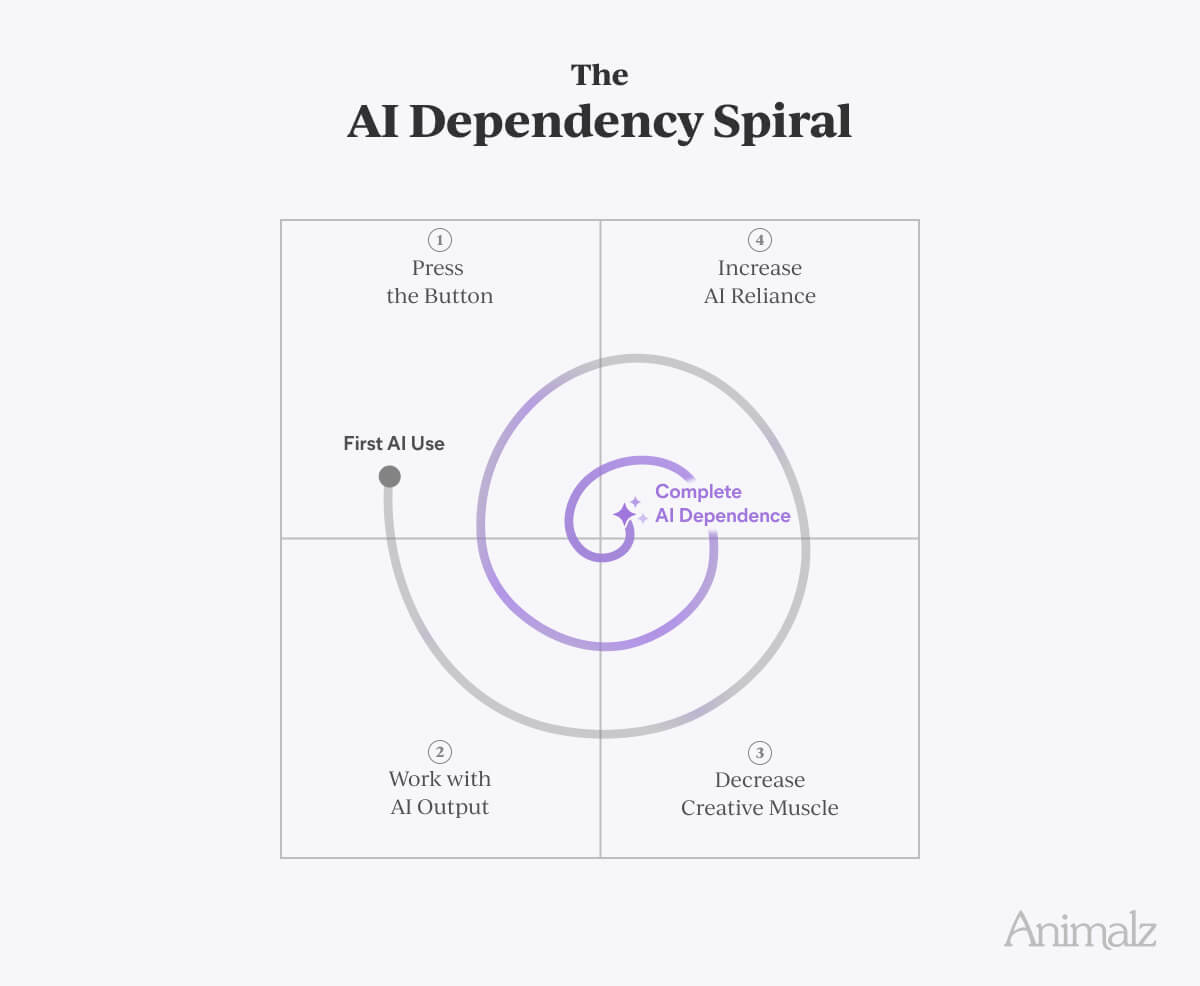
Avoiding that is easier than it sounds. Build small rituals that put some distance between you and the AI:
- Sketch out a Playbook diagram on paper.
- Spread brief and draft review across multiple people.
- Print out a Playbook’s instructions and improve them with a pen.
- Read a piece out loud before you send it out.
These are speed bumps. They force you to slow down and think at the moments that matter, so the judgment stays yours.
Let the computer do more of the work. Just don’t forget that the work that counts is still yours.
Get the latest on AI content & marketing
Get the latest in growth and AI workflows delivered to your inbox each week

.avif)

